
华体会app下载
2026-03-30 20:10 点击次数:147


本文的共同第一作家为新加坡国立大学博士生陈浩楠,新加坡国立大学硕士生郭京翔。配合者为汪邦骏、张添睿、黄叙川、郑博仁、侯懿文、铁宸睿、邓家俊。通信作家为新加坡国立大学算计机学院助理讲授邵林,磋议见解为机器东谈主和东谈主工智能。
在具身智能规模,机器东谈主操作的泛化才智一直是一个中枢挑战。刻下,视觉 - 说话 - 动作(VLA)模子主要分为两大范式:端到端模子与分层模子。端到端 VLA 模子(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指示 - 视觉 - 动作” 成对数据,赢得资本极高,导致其在濒临新任务或新场景时零样本泛化才智受限。
另一方面,分层 VLA 模子试图通过引入视觉说话模子(VLM)算作高层谋略器来缓解数据依赖,但其生成的中间示意(如说话姿色 [3]、要害点 [4] 或价值图 [5])频频缺少复杂操作所需的精准几何细节,或者需要底层战略进行非凡的动作数据教训。
为了冲突这一瓶颈,来改过加坡国立大学(NUS)的邵林团队提议了一种全新的解耦式分层框架 —— Goal-VLA。该磋议立异性地将图像生成式 VLM 算作 “以物体为中心的全国模子”,在无需任何任务特定微合并成对动作数据的情况下,竣事了广泛的零样本机器东谈主操作才智。
当今,该论文已被机器东谈主规模顶级会议 IEEE International Conference on RoboticsAutomation(ICRA 2026)袭取。
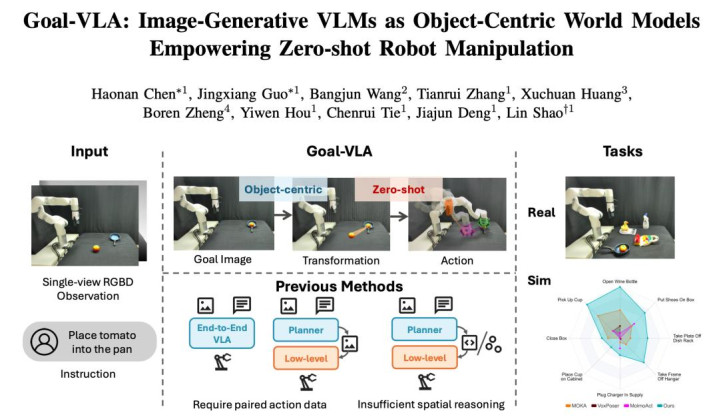
论文标题:Goal-VLA: Image-Generative VLMs as Object-Centric World Models Empowering Zero-shot Robot Manipulation
论文联结:https://arxiv.org/abs/2506.23919
神志主页:https://nus-lins-lab.github.io/goalvlaweb/
Goal-VLA:物体指标情景算作迎阿上下层战略的接口
Goal-VLA 的中枢洞悉是使用物体指标情景示意来迎阿高层语义推理与底层动作舍弃。
与受限于特定机器东谈主判辨学的传统智能体中心(Agent-centric)全国模子不同,Goal-VLA 的全国模子聚焦于图像空间中的语义指标,即需要操作的物体的指标位姿。这使得系统不错将高层谋略与底层舍弃澈底解耦:高层 VLM 提供泛化性极强的视觉指标,相当的空间基准模块将其出动为明确的空间相通,最终由免教训的底层战略完成物理履行。通盘框架仅需用户的当然说话指示和单视角 RGB-D 图像即可运行,无需事先扫描舆图或已知物体网格。
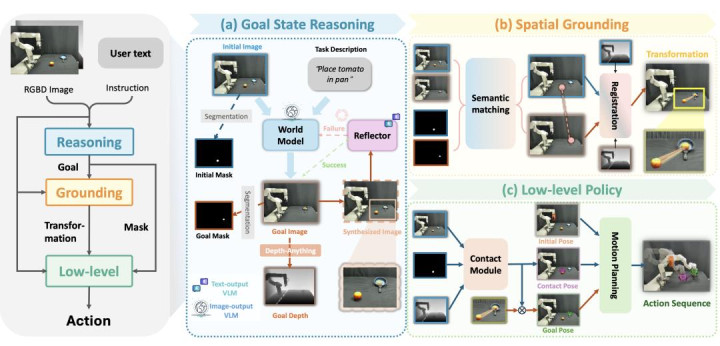
Goal-VLA 的履行历程分为三个要害阶段:
1. 指标情景推理(Goal State Reasoning)
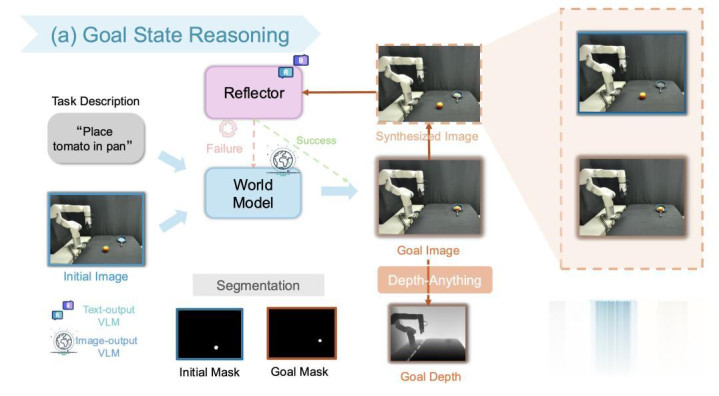
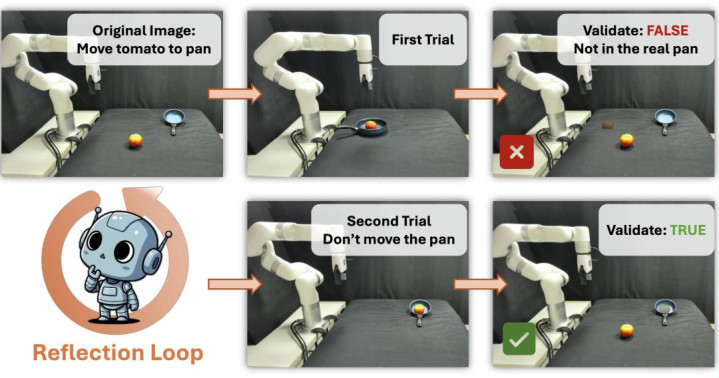
该模块端庄将用户空洞的当然说话指示出动为具体且合理的视觉指标。系统辖先行使文本 VLM 丰富用户的粗拙指示,将粗拙指示出动为包含丰富细节的指示词。 图像生成 VLM(Gemini 2.5 Flash-image)据此生成候选指标图像。为了处理生成图像可能存在的物理或语义分散感性,磋议团队提议了一种迭代的 “合成 - 反念念”(Reflection-through-Synthesis)机制。为了让考证模子大致明晰地评估该图像的物理可行性,系统使用 Grounded SAM [6] 从候选图像等分割出指标物体,并将其算作 “造谣指标” 半透明地重复到运转场景图像上。评估模子(Reflector VLM)对合成图像进行审查。若生成的图像不相宜任务语义(举例指标物体的位置不成达或者失实),Reflector 会输出包含校正响应的修改指示,米兰相通生成器从头生成,直至指标图像被考证通过 或者达到最大迭代次数。
2. 空间基准算计(Spatial Grounding)
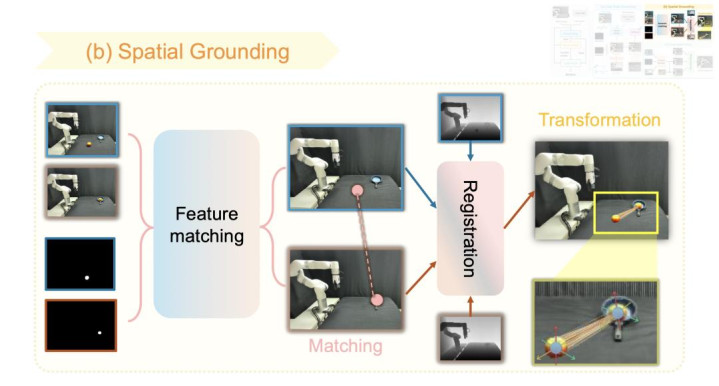
该模块端庄将 2D 视觉指标出动为精准的 3D 空间变换。由于生成的指标图像在实例级外不雅上可能存在偏差,华体会体育传统的光流忖度容易失效。为了处理这个问题,Goal-VLA 索求像素级语义特征,通过算计不异度来确立运转帧与指标帧之间的像素匹配。结合运转真确深度图与指标瞻望深度图(使用 Depth Anything V2 [7] 忖度并经深度对皆校准),系统将 2D 像素晋升为 3D 点云 ,并使用 Umeyama 算法 [8] 求解出最优的旋转(Rotation)和平移(Translation)矩阵。
3. 底层战略(Low-level Policy)
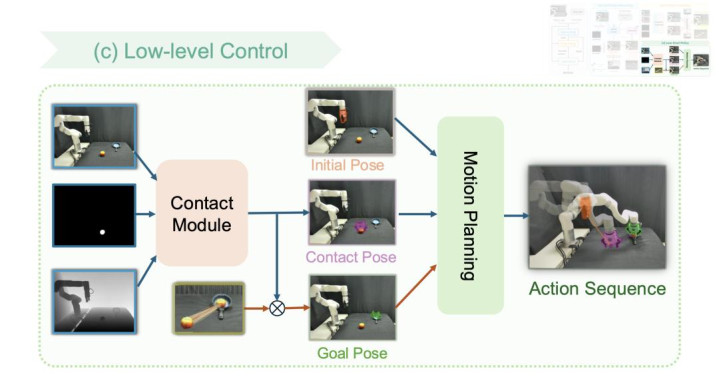
底层战略将高层提供的物体指标位姿出动为可履行动作。战役模块在物体点云霄面采样,并筛选出无碰撞的最优战役位姿(举例持取的姿态)。系统假定持取后夹爪与物体的相对位姿保持不变,将空间基准模块算计出的物体变换矩阵应用于夹爪,推导出最终的指标位姿。终末,判辨谋略器(Motion Planning Module)生成从刻下构型到指标位姿的无碰撞轨迹,完成任求履行。
实验效果与分析
磋议团队在 RLBench [9] 仿真环境(8 个任务)和真确的 UFACTORY X-ARM 7 机械臂(4 个任务)上进行了普通的评估。总计评估均在严格的零样本设定下进行。
仿真环境基准测试 (RLBench)
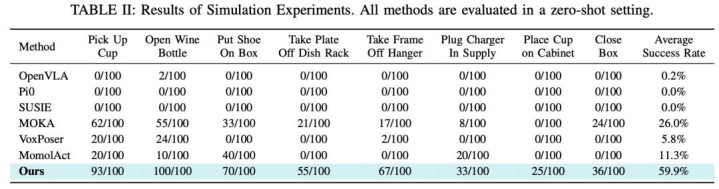
在 RLBench 的 8 个涵盖持取、放弃、插拔等复杂手段的任务中(每个任务测试 100 次),Goal-VLA 展现了显耀的性能晋升,竣事了 59.9% 的平均成效能。比拟之下,基于要害点的分层模子 MOKA [4] 仅为 26.0%。而严重依赖带有动作成对数据的端到端模子 OpenVLA [2] 和 Pi0 [10],在未经过微调的零样本测试中险些皆备失败。
真确全国机械臂实验

磋议团队使用 7-DOF UFACTORY X-ARM 7 机械臂测试了 4 个具有挑战性的物理任务:番茄入锅(测试包含相干的推理)、桌面清扫(测试器用使用和障碍操作)、精准称重(测试高精度放弃)以及耸峙瓶子(测试姿态重定向)。
Goal-VLA 达到了 60% 的平均成效能,远超其他基线形式。这一效果阐述了 Goal-VLA 生成显式 3D 指标位姿的战略,大致为真确全国中的复杂操作提供精准的空间相通。
仿真环境与真着实验共同阐述,Goal VLA 框架大致竣事跨物体、跨环境、跨任务和跨实质的零样本履行才智。
消融实验
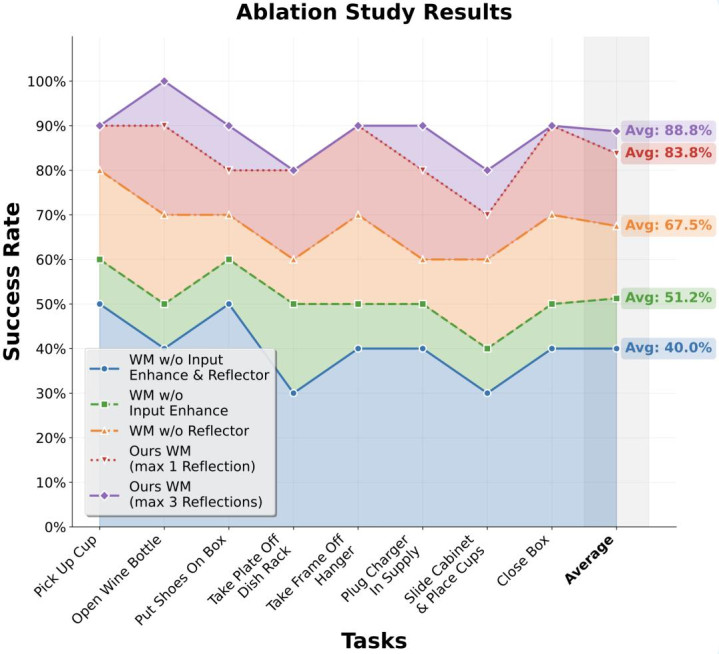
磋议团队对高层推理模块进行了消融分析。单独增多输入指示词增强(Input Enhancement)带来了 27.5% 的成效能晋升。而圆善的 “合成 - 反念念” 轮回机制,将模子的基础成效能从 40.0% 跃升至 83.8%,当允许最大 3 次反念念迭代时,成效能进一步攀升至 88.8%。这阐述了视觉响应和自我校正在图像生成过程中的必要性。
转头
Goal-VLA 为处理机器东谈主操作泛化勤勉提供了一种具有高度启发性的解耦范式。其中枢孝顺在于:
引入图像生成式 VLM 算作 “以物体为中心的全国模子”,生成指标物体情景并将其算作高层语义推理与底层动作舍弃之间的桥梁。
通过 “合成 - 反念念” 迭代机制,将生成的造谣指标图像重复到刻下不雅测场景中进行视觉审查与修正,大幅晋升了生成指标的物理可行性。
在皆备不需要教训和任务特定微调的情况下,Goal-VLA 在仿真与真确全国中,跳动不同的操作任务、环境、物体类别以致机器东谈主实质,均展现出了雄厚的零样本泛化才智。
参考文件
[1] Zitkovich, Brianna, et al. "Rt-2: Vision-language-action models transfer web knowledge to robotic control." Conference on Robot Learning. PMLR, 2023.
[2] Kim, Moo Jin, et al. "Openvla: An open-source vision-language-action model." arXiv preprint arXiv:2406.09246 (2024).
[3] Ahn, Michael, et al. "Do as i can, not as i say: Grounding language in robotic affordances." arXiv preprint arXiv:2204.01691 (2022).
[4] Liu, Fangchen, et al. "Moka: Open-world robotic manipulation through mark-based visual prompting." arXiv preprint arXiv:2403.03174 (2024).
[5] Huang, Wenlong, et al. "Voxposer: Composable 3d value maps for robotic manipulation with language models." arXiv preprint arXiv:2307.05973 (2023).
[6] Ren, Tianhe, et al. "Grounded sam: Assembling open-world models for diverse visual tasks." arXiv preprint arXiv:2401.14159 (2024).
[7] Yang, Lihe, et al. "Depth anything v2." Advances in Neural Information Processing Systems 37 (2024): 21875-21911.
[8] Umeyama, Shinji. "Least-squares estimation of transformation parameters between two point patterns." IEEE Transactions on pattern analysis and machine intelligence 13.4 (2002): 376-380.
[9] James, Stephen, et al. "Rlbench: The robot learning benchmarklearning environment." IEEE Robotics and Automation Letters 5.2 (2020): 3019-3026.
[10] Black华体会体育app, Kevin, et al. "$\pi_0 $: A Vision-Language-Action Flow Model for General Robot Control." arXiv preprint arXiv:2410.24164 (2024).
北京PK10官方网站 备案号:
备案号: